Workshop
Workshop on Theoretical Advances in Deep Learning will take place at the Istanbul Center for Mathematical Sciences. The venue is located inside the Bogazici University main campus. Click on the arrow to expand for further details below.
Dates
Tuesday, July 30 - Friday, August 2, 2019
Location
Istanbul Center for Mathematical Sciences
About
Abstract: During the past few years, differentiable programming as a paradigm of deep learning provided cutting edge applications of machine learning in large scale problems in wide areas covering vision, speech, translation, and various autonomous machines. However, the success rate of working models is much faster than the scientific progress on understanding the working principles of such systems. More recently, theoretical developments shed some light on the inner workings of toy models on simple tasks, yet the community is still missing theoretical results that have strong predictive power on what to expect from large scale models on complex tasks and how to design them to improve their performance. In an attempt to move towards deeper understanding, we aim to bring together a group of researchers interested in the theoretical understanding of deep learning. The workshop is devoted to reviewing the most recent literature to bring everyone at the same level in terms of our current understanding, further, we will discuss theoretical challenges and propose ways to move forward. We will also devote one day of the workshop to interact with the local machine learning community that will include an opportunity for interested advanced students to introduce themselves and we will have a public lecture covering current trends in machine learning.
Topics:
- Toy models that exhibit characteristic features of large scale systems
- Scaling laws of neural networks with their degrees of freedom
- Algorithmic effects and regularization in training neural networks
- The role of the structure in data and teacher-student networks
- Limiting behavior of simple models
- Statistical physics approach to neural networks implications and its limits
- The role of priors on the performance of models
Commute
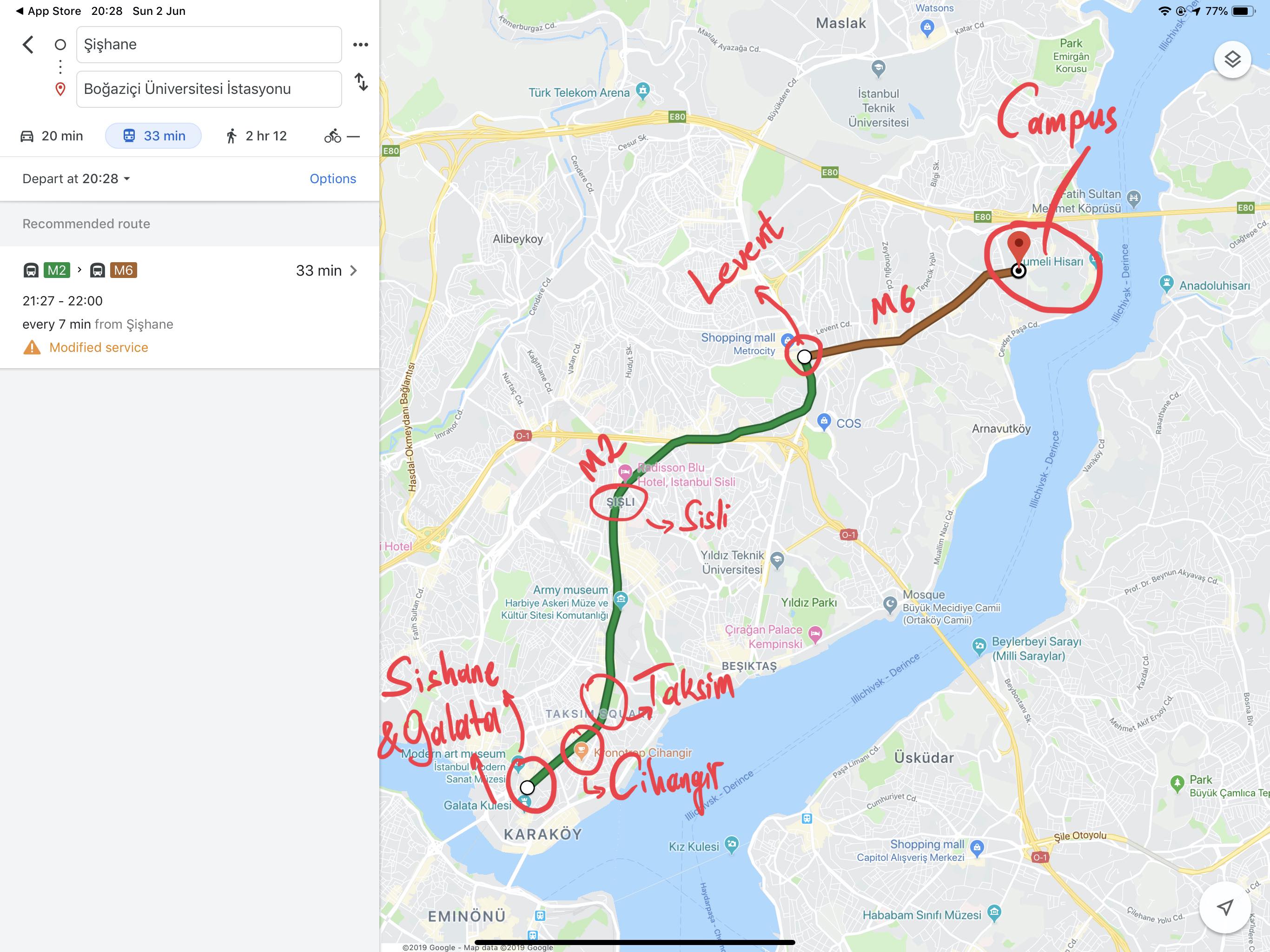
The subway station next to the campus is Bogazici Universitesi Istasyonu. It is the last stop on line M6. Take line M2 (goes through Taksim) and transfer at the station called Levent (you can’t miss it!).
Commute to Bogazici University South Campus
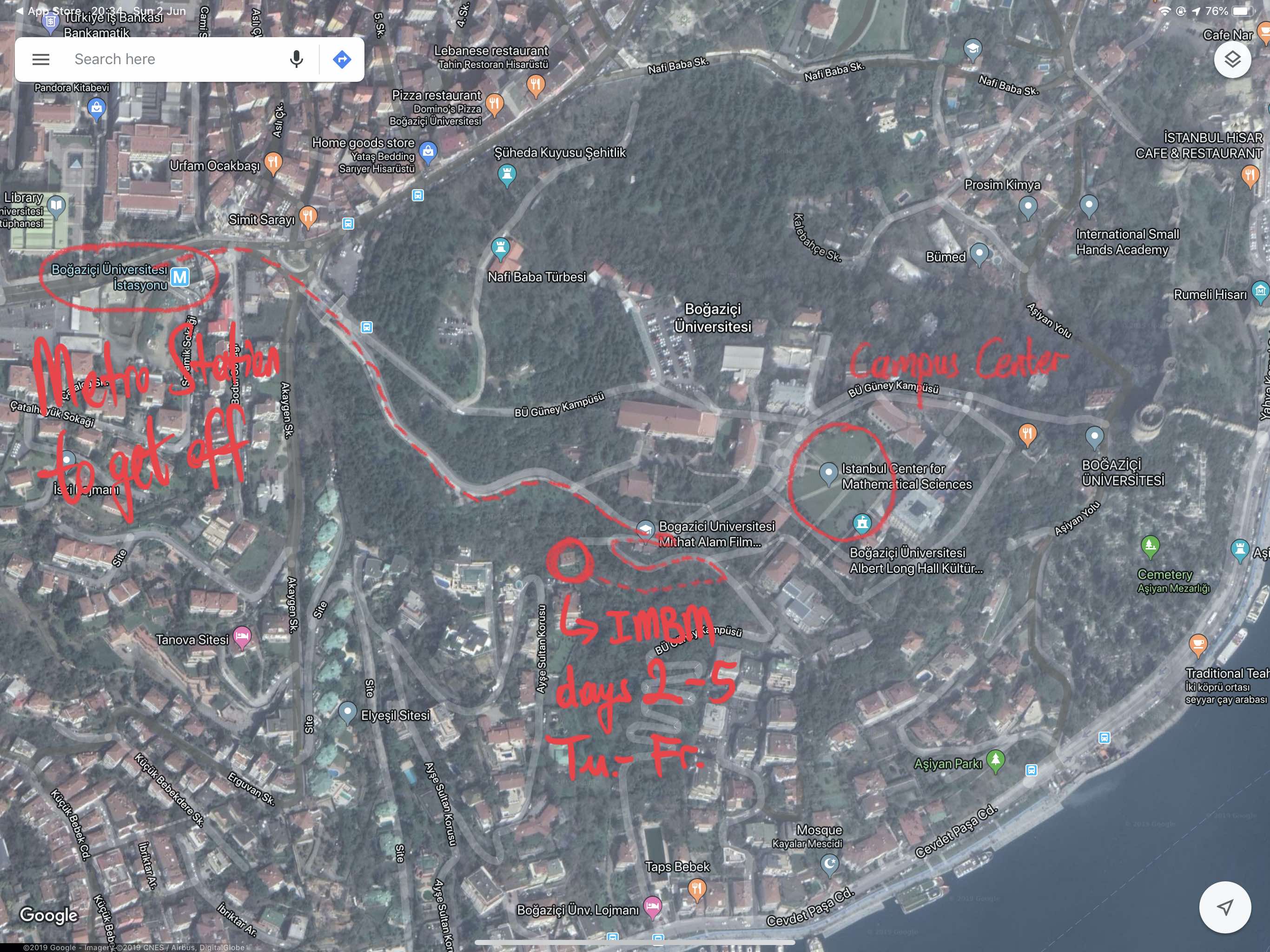
 Closer look at the South Campus
Closer look at the South Campus
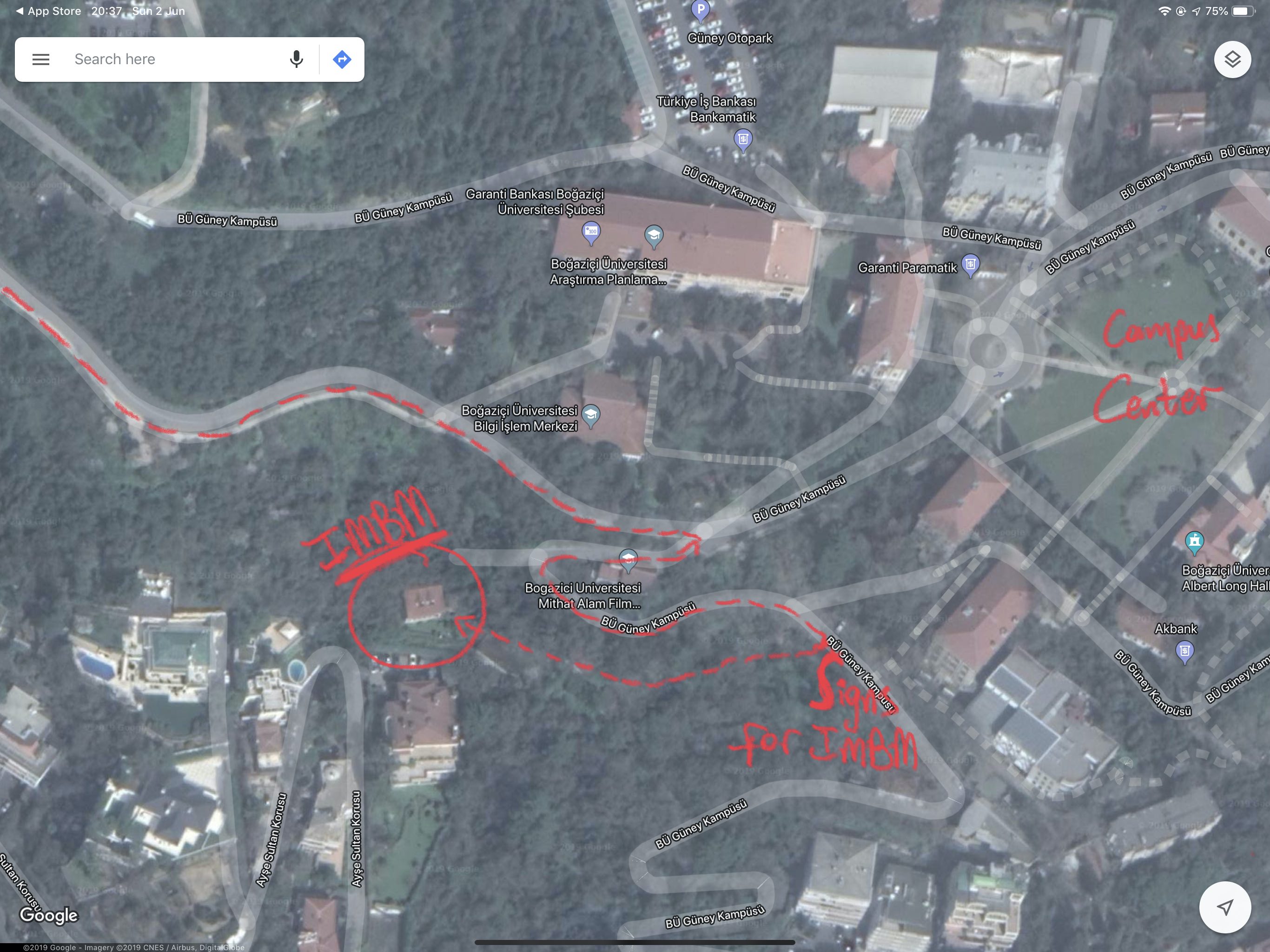
 Zooming in on IMBM
Zooming in on IMBM
Participants
- Ethem Alpaydin, Ozyegin University
- Anima Anandkumar, Caltech & NVIDIA
- Benjamin Aubin, ENS
- Aristide Baratin, MILA
- David Belius, University of Basel
- †Giulio Biroli, ENS
- Chiara Cammarota, King's College London
- Stephane d'Ascoli, ENS
- Ethan Dyer, Google
- Alp Eden, Bogazici University (retired)
- Utku Evci, Google
- Chiara Facciola, MOX - Politecnico di Milano
- Orhan Firat, Google
- Silvio Franz, Universite Paris-Sud
- Marylou Gabrie, ENS
- Surya Ganguli, Stanford
- *Mario Geiger, EPFL
- Caglar Gulcehre, DeepMind (over VC)
- Mert Gurbuzbalaban, Rutgers Business School
- Clement Hongler, EPFL
- Sungmin Hwang, LPTMS
- Melih Iseri, USC
- Duygu Islakoglu, Koc University
- Arthur Jacot, EPFL
- Mehmet Kiral, Sophia University
- Florent Krzakala, ENS
- Fabian Latorre, EPFL
- Ioannis Mitliagkas, MILA
- Muhittin Mungan, Uni Bonn
- Brady Neal, MILA
- Behnam Neyshabur, NYU
- Mihai Nica, University of Toronto
- Ekin Ozman, Bogazici University
- Vardan Papyan, Stanford
- Dan Roberts, Diffeo Labs
- Miguel Ruiz Garcia, University of Pennsylvania
- †Levent Sagun, EPFL
- Stefano Sarao, CEA
- Andrew Saxe, University of Oxford
- Berrenur Saylam, Bogazici University
- David Schwab, CUNY
- Berfin Simsek, EPFL
- Sam Smith, DeepMind
- Stefano Spigler, EPFL
- Eric Vanden-Eijnden, NYU
- †Matthieu Wyart, EPFL
- Sho Yaida, Facebook AI
- Lenka Zdeborova, CEA
†: Organizers, *: To be confirmed
Program
Each session will include three to five 30-minute talks (25 + 5) which are followed by a joint Q&A for that session. During after hours and weekends, the venue will be available for informal discussions. The detailed schedule is below.
| Tuesday, July 30 |
|---|
| 09:00-09:30 Orhan Firat, Revisiting Recent Neural Net Theory at Scale |
| 09:30-10:00 Surya Ganguli, Understanding the first steps of vision through interpretable deep learning |
| 10:00-10:30 Coffee break |
| 10:30-11:00 Brady Neal, Over-Parametrization in Deep RL and Causal Graphs for Deep Learning Theory |
| 11:00-11:30 Florent Krzakala, Some Results on One and Two Layer Neural Nets |
| 11:30-12:00 Joint Q&A and Discussion |
| 12:00-13:30 Lunch Break |
| 13:30-14:00 Sam Smith, Practical Insights into SGD Hyper-parameters |
| 14:00-14:30 Mert Gurbuzbalaban, A Tail-Index Analysis of Stochastic Gradient Noise in Deep Neural Networks |
| 14:30-15:00 Mihai Nica, Gradients of ReLU Networks on Initialization |
| 15:00-15:30 Coffee Break |
| 15:30-16:00 Chiara Cammarota, Replicated Gradient Descent |
| 16:00-16:30 Stefano Spigler, Asymptotic Learning Curves of Kernel Methods |
| 16:30-17:00 Joint Q&A and Discussion |
| Wednesday, July 31 |
|---|
| 09:00-09:30 Clement Hongler, Neural Tangent Kernel |
| 09:30-10:00 Eric Vanden-Eijnden, Trainability and Accuracy of Neural Networks: An Interacting Particle System Approach |
| 10:00-10:30 Coffee break |
| 10:30-11:00 Mario Geiger (presented by Matthieu Wyart), On the benefits of over-parametrisation: Lazy vs feature learning |
| 11:00-11:30 Arthur Jacot, Freeze and Chaos for DNNs: an NTK view of Batch Normalization, Checkerboard and Boundary Effects |
| 11:30-12:00 Joint Q&A and Discussion |
| 12:00-13:30 Lunch Break |
| 13:30-14:00 Andrew Saxe, High-dimensional dynamics of generalization error in neural networks |
| 14:00-14:30 Ioannis Mitliagkas, A Modern Take on the Bias-Variance Tradeoff in Neural Networks |
| 14:30-15:00 Behnam Neyshabur, Understanding the Generalization of Overparameterized Networks |
| 15:00-15:30 Coffee Break |
| 15:30-16:00 Aristide Baratin, Rethinking Complexity in Deep Learning: A View from Function Space |
| 16:00-16:30 Stephane d’Ascoli, Finding the Needle in the Haystack with Convolutions: on the benefits of architectural bias |
| 16:30-17:00 Joint Q&A and Discussion |
| Thursday, August 1 |
|---|
| 09:00-09:30 Ethan Dyer, Training dynamics of wide networks from Feynman diagrams |
| 09:30-10:00 Dan Roberts, SGD Implicitly Regularizes Generalization Error |
| 10:00-10:30 Coffee break |
| 10:30-11:00 Sho Yaida, Fluctuation-Dissipation Relation for Stochastic Gradient Descent |
| 11:00-11:30 David Schwab, How noise affects the Hessian spectrum in overparameterized neural networks |
| 11:30-12:00 Joint Q&A and Discussion |
| 12:00-13:30 Lunch Break |
| 13:30-14:00 Lenka Zdeborova, Are generative models the new sparsity? Part I |
| 14:00-14:30 Benjamin Aubin, Are generative models the new sparsity? Part II |
| 14:30-15:00 Fabian Latorre, Fast and Provable ADMM for Learning with Generative Priors |
| 15:00-15:30 Coffee Break |
| 15:30-16:00 Silvio Franz, Learning and generalization in quasi-regular environments: a ‘shallow’ theory |
| 16:00-16:30 Vardan Papyan, Three-Level Hierarchical Structure in Deepnet Features, Jacobians and Hessians |
| 16:30-17:00 Joint Q&A and Discussion |
| Friday, August 2 |
|---|
| 09:00-09:30 Marylou Gabrie, On information theory for deep neural networks |
| 09:30-10:00 Utku Evci, The Difficulty of Training Sparse Neural Networks |
| 10:00-10:30 Berfin Simsek, Weight-space symmetry in deep networks: permutation saddles & valleys |
| 10:30-10:50 Joint Q&A and Discussion |
| 10:50-11:10 Coffee Break |
| 11:10-11:40 Stefano Sarao, The Fate of the Spurious: descent algorithms and rough landscapes |
| 11:40-12:10 Sungmin Hwang, Jamming in multilayer supervised learning models |
| 12:10-12:40 Miguel Ruiz Garcia, Dynamical loss functions for machine learning |
| 12:40-13:00 Joint Q&A and Discussion |
| 13:00-15:00 Lunch and Round Table Discussion |